
En janvier 2015 et dans une lettre ouverte, Stephen Hawking, Elon Musk et des experts en intelligence artificielle (IA) ont, ensemble, mis en garde contre les dangers que représente l’IA.
Ils insistent sur la nécessité d’en garder le contrôle.
Si le temps de création d’un skynet et l’arrivée de terminators venus exterminer les humains semble encore lointain, nous voyons déjà apparaître des scandales autour de l’IA, soulevant des questions éthiques pour les drones tueurs par exemple ou dans le cadre de la révélation de pratiques discriminatoires.
Ainsi la première version du logiciel de reconnaissance faciale d’Apple ne reconnaissait pas les visages de couleur noire. L’algorithme de sélection automatique de CV d’Amazon quant à lui privilégiait des candidats masculins plutôt que féminins sur les postes de développeurs.
Les exemples ne manquent pas. De nos jours, les algorithmes sont partout. On les retrouve aussi bien sur Netflix pour nous aider à trouver des séries et films « à notre goût » que sur nos smartphones pour calculer le chemin le plus court d’un point A à un point B. Plus dramatiquement, la justice américaine se fait désormais aider par un algorithme, nommé COMPAS, pour décider d’emprisonner ou non un prévenu. Et ici, la couleur de peau réduit les chances d’échapper à la prison même si l’intention des concepteurs de l’algorithme n’était pas là.
Ces aides se voudraient plus neutres et impartiales que l’humain cependant derrière chaque algorithme se cachent des individus qui les pensent, les construisent, les programment, les testent et potentiellement y insèrent des biais.
Comme dans le langage courant un biais en algorithme signifie que celui-ci peut être influencé de part notre vision parfois déformée des individus, des cultures, etc…. Ils peuvent avoir différentes origines comme le montre l’infographie ci-dessous.
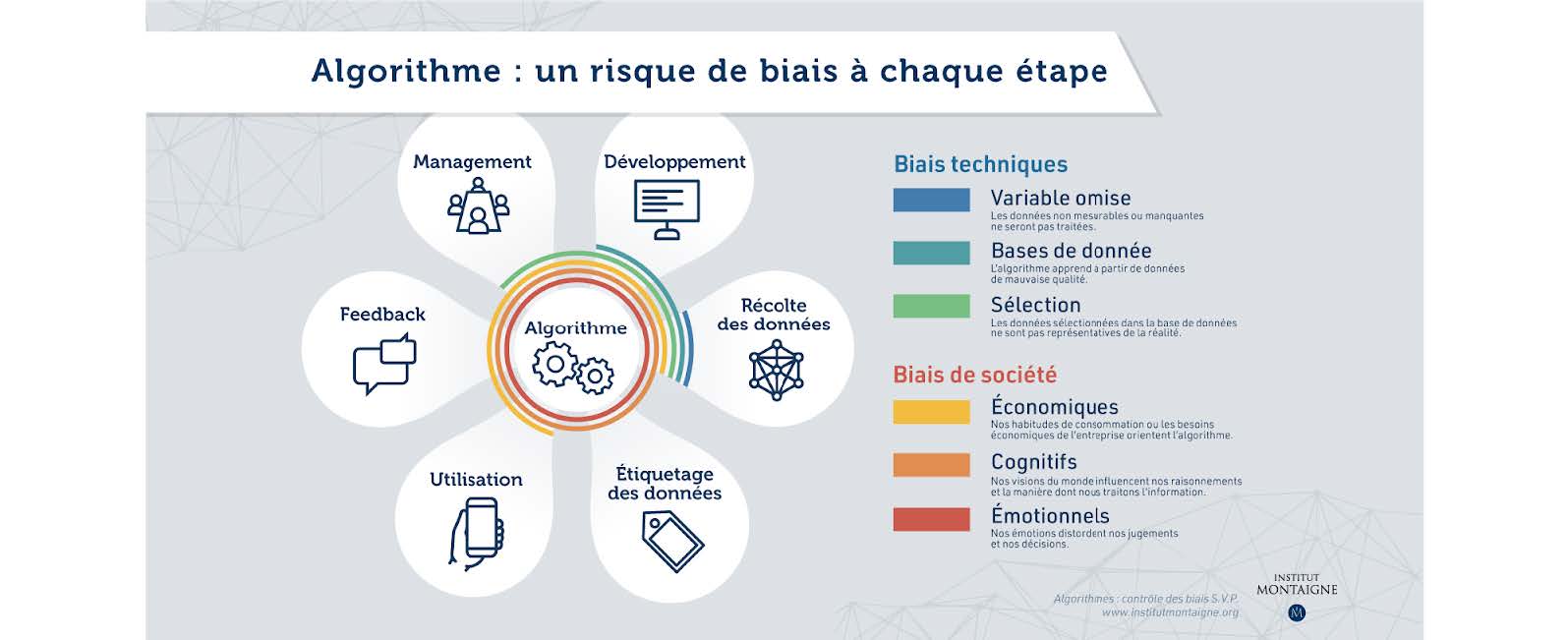
Chaque algorithme créé contient des équations, des variables, des conditions et des hypothèses qui sont choisis de manière explicite par les développeurs ou leurs managers. Et les choix vont être fondés sur le vécu, les présupposés, les croyances de ceux-ci. Souvent de façon inconsciente.
Dans le cas d’Apple, les développeurs étaient principalement des hommes blancs. Leur algorithme résulte de la vision du monde que ceux-ci en avaient. Pour leur algorithme ils ont rentré majoritairement des caractéristiques correspondant à des visages de type caucasien.
Pour Amazon, leur algorithme quant-à lui était calibré sur les embauches des 10 dernières années qui étaient principalement des hommes à ces postes là. Leur échantillon n’était pas assez représentatif et a entraîné des discriminations envers les candidatures féminines.
Il existe d’autres types de biais. Ceux dit implicites.On les retrouve souvent dans le cas de machine learning.
Prenons l’exemple d’un algorithme pour reconnaître automatiquement un chien. Dans un premier temps on rentre tous les critères explicites basiques pour décrire un chien puis on va ensuite présenter des photos contenant un chien ou pas et corriger en cas de mauvaise réponse. L’algorithme va alors développer par lui-même des critères de catégorisation sur lesquels il se basera pour reconnaître un chien.
Ces ensembles de critères générés par l’algorithme à la suite de son apprentissage créent un réseau neuronal avec des configurations de données d’entrées qui donnent différentes réponses. Ces réseaux peuvent devenir si volumineux qu’ils deviennent complexes à analyser surtout dans le cas du deep learning.
Google a d’ailleurs rencontré cette problématique avec son algorithme de labellisation des photos pour identifier les personnes, les animaux ou les objets. Malheureusement, ils se sont aperçus qu’il assimilait de façon malheureuse et dans certains cas les personnes noires à des singes. Google a préféré désactiver son algorithme plutôt que de la « rééduquer » car son réseau neuronal était devenu trop complexe pour être analysé.
Puisque les biais algorithmiques peuvent engendrer des discriminations ou des choix douteux sur le plan éthique, il est important que les entreprises qui les développent tout comme les personnes qui les utilisent, restent vigilantes sur le sujet.
Les utilisateurs en restant objectifs et critiques envers ces aides à la décision et les entreprises en instaurant des bonnes pratiques afin de prévenir, détecter et corriger ces biais.
Il est frappant de savoir que les juges américains n’ont pas accès aux critères retenus par l’algorithme COMPAS(évoqué plus haut) pour des raisons de protection commerciale de la société qui a développé l’outil.
De grandes entreprises comme Google ou IBM se sont penchés sur le sujet et proposent des outils open sources pour aider à la détection et à la correction de bias. Il y a What-If Tool (WIT) pour Google ou AI Fairness 360 pour IBM.
L’OCDE (Organisation de coopération et de développement économique) s’intéresse également au sujet. En mai 2019, ses États membres ont signé le premier ensemble de principes intergouvernementaux sur l’intelligence artificielle (IA) visant à assurer la conception de systèmes d’IA robustes, sûrs, équitables et dignes de confiance.
Le sujet est très vaste. De nombreux débats sont en cours pour savoir comment définir l’équité dans les algorithmes pour l’IA. L’institut Montaigne a d’ailleurs publié un article qui propose des solutions pour prévenir ces biais.
https://www.institutmontaigne.org/publications/algorithmes-controle-des-biais-svp
Pour ma part, j’ai pris connaissance du sujet au travers d’un livre “De l’autre côté de la machine, voyage d’une scientifique au pays des algorithmes » d’Aurélie Jean dont je ne saurais que vous en conseiller la lecture.

par Hélène MERLIER – Développeuse DATA à PROXIAD NORD
