
Caching is hard!
Si les bonnes pratiques du cache HTTP sont maintenant bien établies, GraphQL, en permettant à chaque client d’éxecuter des requêtes très dynamiques, présente plusieurs challenges.
Dans cette présentation, nous ferons une rapide présentation de GraphQL et des principales différences avec REST. Nous verrons comment le système de type permet de construire un cache normalisé, type safe et persistant.
Enfin, nous montrerons comment l’utiliser en pratique dans une App d’exemple Android.
Cet article est un résumé de la conférence donnée par Benoit Lubek et Martin Bonnin lors du devfest 2022
GraphQL, qu’est-ce que c’est ?
GraphQL, pour Graph Query Language, est un langage qui permet de décrire et d’exécuter des API grâce à :
- un schéma, qui gère aussi la nullabilité ainsi que la déprécation des champs
- des types (Int, Float, String, Boolean)
- des objets
- des interfaces
- des listes.
GraphQL met en place une introspection des API, ce qui signifie que l’API est auto-documentée. On peut alors interroger un endpoint directement pour récupérer son schéma (champs possibles, types, etc …). Ainsi, l’avantage de GraphQL réside dans le fait qu’il n’y a besoin plus que d’un seul endpoint pour adresser tous les cas d’utilisation d’une API.
Prenons l’exemple d’une API REST à laquelle plusieurs types de support (ordinateur, smartphone, etc.) vont faire appel, avec des besoins de champs différents.
Une telle API devra alors soit exposer un endpoint unique avec tous les champs utilisables, soit exposer un endpoint pour chaque support.
Grâce à GraphQL, un seul endpoint a besoin d’être exposé, et chaque support pourra requêter uniquement les champs dont il a besoin.
GraphQL, comment ça marche ?
Une requête GraphQL s’exprime dans une syntaxe proche du JSON. Il suffit de lister les champs que l’on veut récupérer ainsi que les champs des sous-objets pour les types composites.
Requête
query UserQuery {
user {
id
login
avatar {
small
medium
}
}
}Réponse
{
"data": {
"user" {
"id": 42,
"login": "demo",
"avatar" {
"small": "...",
"medium": "..."
}
}
}
}Si l’on enlève un champ de la requête, le champ disparaîtra également de la réponse, ce qui a un impact sur le caching.
Traditionnellement, pour mettre en cache des informations sur mobile, une base de données relationnelle (SQLite) est utilisée et chaque champ des API REST est mappé à une colonne d’une table.
Cependant, ce procédé ne fonctionne pas avec GraphQL car on ne récupère pas d’objet entier mais uniquement les champs demandés. On ne peut pas simplement créer des colonnes avec des valeurs à null pour les données non demandées car GraphQL peut retourner la valeur null ayant possiblement une signification métier. On ne peut pas non plus créer une table par requête ou stocker chaque payload JSON, comme cela entrainerait une redondance des données qui ferait augmenter inutilement la taille du cache.
Caching de GraphQL, comment faire ?
Une solution trouvée chez Apollo est de ne pas stocker les réponses dans des table structurées, mais de stocker les retours dans des listes de Record. Plus simplement, un Record peut être représenté par une Map.
Afin d’enregistrer les données en cache, les réponses GraphQL sont mises à plat.
Origine
{
"data": {
"user": {
"id": 42,
"email": "test@proxiad.com",
"login": "test",
"name": "Test Heure"
}
}
}Aplati
{
"data": {
"user": CacheReference("42")
},
"42": {
"id": 42,
"email": "test@proxiad.com",
"login": "test",
"name": "Test Heure"
}
}data devient un premier Record qui contient un objet user, une CacheReference pointant vers le Record du user ayant l’id 42.
Si l’on reçoit une nouvelle réponse avec un champ supplémentaire pour le user 42, il suffira alors de merger les Record pour ajouter le nouveau champ au cache.
{
"42": {
"id": 42,
"email": "test@proxiad.com",
"login": "test",
"name": "Test Heure",
// new Record field
"avatarUrl": "http://..."
}
}Cependant, ici on s’est basé sur l’id de l’utilisateur. Hors, ce champ peut ne pas être présent dans les schémas. Dans ce cas, une solution peut être d’utiliser le chemin vers la data comment identifiant en cache :
{
"data": {
"user": CacheReference("data.user")
},
"data.user": {
"email": "test@proxiad.com",
"login": "test",
"name": "Test Heure"
}
}Une nouvelle fois, cette solution n’est pas optimale, car un même user peut être représenté avec un chemin différent dans le graphe, entraînant une duplication de données.
Il est donc très important de bien définir ses identifiants lorsque l’on veut faire du caching avec GraphQL.
Comment lire les données dans le cache
Le stockage des données sous forme de Record dans le cache entraîne la perte de leur typage. Cependant grâce au schéma de GraphQL, il est possible de le retrouver. Pour, par la suite, relier les types aux données venant du cache, plusieurs outils existent comme par exemple la librairie open source Apollo Kotlin.
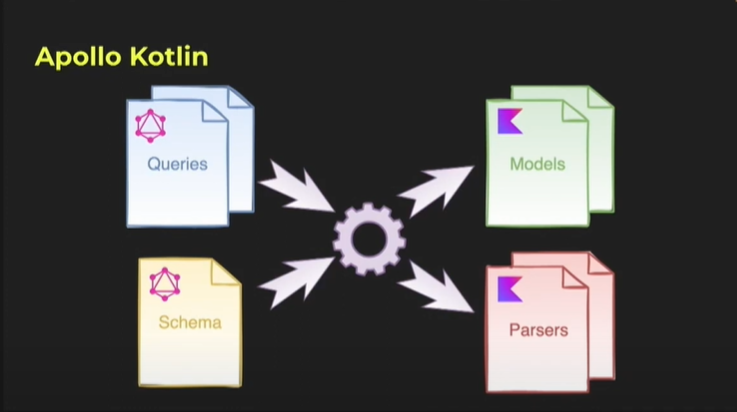
Apollo est un client GraphQL qui génère du code à partir des requêtes et du schéma de l’API, afin de créer des Models et des Parsers. Ces Parsers vont populer les Models grâce aux informations venant en réponse de la requête.
Apollo Kotlin embarque également dans sa libraire le système de cache normalisé que nous avons vu précédemment.
Exemple
Nous allons maintenant voir comment utiliser cette librairie avec un exemple en Kotlin adapté pour des applications Android.
Initilisation du cache et du client
val memoryCache = MemoryCacheFactory(maxSizeBytes = 5_000_000) // cache en mémoire
val apolloClient: ApolloClient = ApolloClient.builder()
.serverUrl(SERVER_URL)
.normalizedCache(memoryCache)
.build()
On définit simplement un cache (ici en mémoire). Ce cache est donné au client lors de son initialisation. À partir de ce moment, toutes les requêtes passeront par le cache.
Il est possible de créer un cache persistant en base SQLite :
val sqlCache = SqlNormalizedCacheFactory(context, "app.db")Il est également possible de chaîner les caches et donc de stocker les données en mémoire et en base. De cette manière, nous avons les avantages de la rapidité du cache mémoire et d’un fallback vers la base SQLite.
val memoryThenSqlCache = memoryCache.chain(sqlCache)Watchers
Apollo permet également la mise en place de watchers, qui vont écouter les mises à jour du cache pour lancer des actions (mettre à jour une UI par exemple) :
mutation {
updateUser({id: "42", status: "Entrain de lire un article"}) {
id
status
}
}Conclusion
Dans cet article, nous avons vu comment Apollo permet de gérer facilement un cache normalisé et typé pour une application utilisant des API GraphQL. Le cache permet de maintenir une certaine réactivité même en cas d’absence de réseau ou limite la consommation de bande passante dans le cas contraire.
Sources
- Rediffusion de la conférence donnée lors du devfest 2022 : https://www.youtube.com/watch?v=5CgNlSuqPOU
- Github du projet Apollo Kotlin : https://github.com/apollographql/apollo-kotlin
Direction Technique
Stéphane YVON
Proxiad NORD
